The Need for Machine Learning Design Patterns

What Are Design Patterns?
Design patterns are proven, reusable solutions to common problems in software design.
The Machine Learning Design Patterns book presents a collection of such patterns drawn from real-world machine learning projects. Its main goal is to provide standardized solutions to recurring challenges in ML system design.
Machine Learning Terminology
Models and Frameworks
Machine learning is a new programming paradigm that focuses on building mathematical models capable of learning patterns from data without being explicitly programmed.
Machine learning problems can be divided into two main types: Supervised Learning and Unsupervised Learning.
Supervised Learning: refers to problems where the ground truth labels are known. The model makes predictions, which can then be compared to the actual labels to evaluate performance.
Unsupervised Learning: on the other hand, applies when the ground truth labels are unknown. The goal is to explore the structure of the data, which typically involves:
- Clustering: grouping similar items or elements based on shared characteristics.
- Dimensionality Reduction: compressing data by reducing the number of input features. This improves computational efficiency and reduces memory usage.
With supervised learning, problems can be defined as either Regression, which predicts continuous values (e.g., house price prediction), or Classification, which predicts probabilities mapped to predefined categories (e.g., image recognition – Cat or Dog?).
Data and Feature Engineering
Data is the core of any machine learning problem. A dataset refers to the data used to train and evaluate ML models. Typically, we split the dataset into three subsets:
- Training set: used to train the model. It usually makes up the largest portion, around 70% to 80% of the total dataset.
- Validation set: machine learning models have many hyperparameters that depend on the problem. As a data scientist, your job is to tune these parameters. For this, we perform hyperparameter tuning using the validation set.
- Test set: this data is not used during training. The model should never see it. Its primary purpose is to evaluate the model’s performance.
The data should be split in a way that ensures all subsets (training, validation, and test) have similar statistical properties.
There are many splitting strategies, and the choice depends on the problem at hand — though they are not discussed in detail in this chapter. Generally, we use a random split. However, for problems like time series, we use time-aware splitting methods.
Before feeding the data into your model, several steps must be considered, referred to as data preprocessing and feature engineering. This involves feature scaling, converting non-numerical values (e.g., text) to numerical values using techniques like categorical encoding, handling missing values, etc.
Job Roles – Data
Within a company, there are many different job roles related to Data and Machine Learning:
Data Scientists: focus on understanding business problems, performing Exploratory Data Analysis (EDA), building initial models, and providing insights to support better decision-making. Data scientists often work in notebook environments, focus on applied research, implement models from research papers, compare approaches, and select the best models and architectures.
Machine Learning Engineers: apply software engineering principles to ML.
They take models developed by data scientists and deploy them into production environments. They manage infrastructure and operations for training and serving models, following MLOps best practices such as model updating, versioning, and serving, etc.Data Engineers: are responsible for the flow of data—building Extract, Transform, Load (ETL) pipelines, managing data storage systems (Data Warehouses, Data Lakes, etc.), and ensuring data quality. They make data accessible to data scientists, analysts, and other stakeholders.
Research Scientists: primarily focus on developing new algorithms or approaches.
They spend most of their time on prototyping and evaluating novel methods in machine learning.Data Analysts: gather insights from data, often working closely with product teams to understand how those insights can solve business problems and create value. While data scientists focus on making predictions (the future), data analysts focus on understanding historical data. Rather than predicting an event, analysts aim to explain why an event happened. Data analysts can upskill over time to transition into data science roles.
Developers: they often consume the model’s predictions via APIs deployed by ML engineers. These predictions are then used and integrated into user-friendly interfaces, such as web and mobile applications.
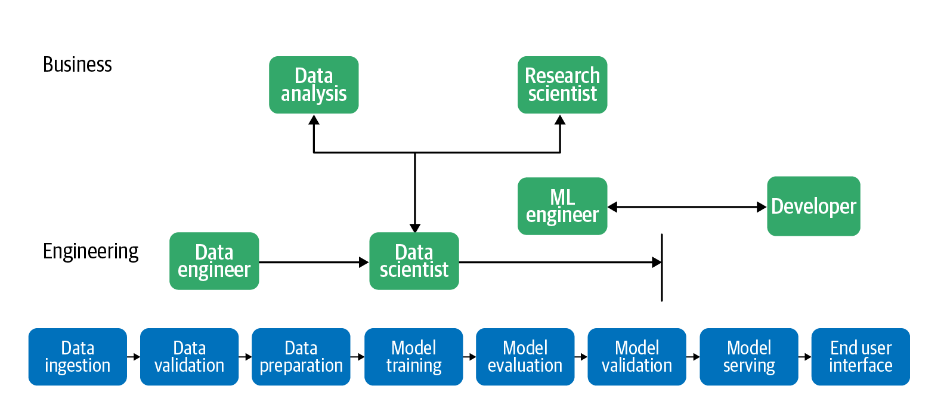 Figure: Job Roles – Data
Figure: Job Roles – Data