RAG: The 2025 Best-Practice Stack

Overview
This talk presents the 2025 best-practice stack for building RAG (Retrieval-Augmented Generation) applications using open-source tools. Key takeaways include:
- Core components: Orchestration, Vector Databases, Enhanced Retrieval, Evaluation
- Practical tips on chunking, retrieval, and data strategies
- A reference stack for scalable and accurate RAG pipelines
What is RAG?
RAG = Dense Vector Retrieval + In-Context Learning
It augments language models with external knowledge by retrieving relevant context from your data. The typical flow:
- Retrieve: Search your documents for relevant content
- Augment: Add retrieved context to your prompt
- Generate: Produce more accurate, grounded responses
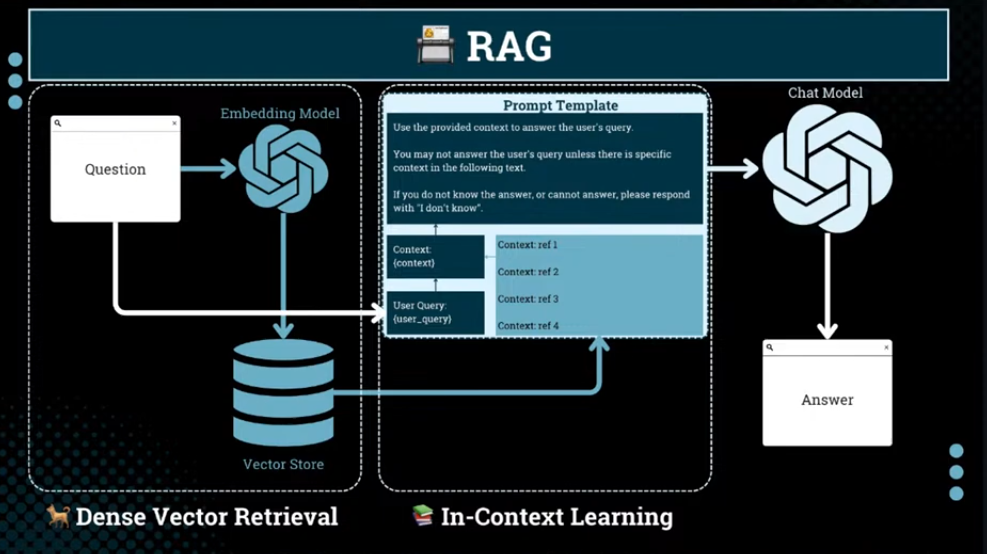 Figure: Basic RAG Architecture – Embeddings + In-Context Learning
Figure: Basic RAG Architecture – Embeddings + In-Context Learning
Key Insights from the Talk
- Orchestration Framework
- LangChain: More flexible, better suited for complex workflows
- LlamaIndex: Simpler, often easier to start with
- Vector Database
- Qdrant: High performance, scales well from small to millions of documents
- Embedding Models
- Depends on your use case: language coverage, speed, and accuracy matter
- Evaluation Framework
- RAGAS: Open-source tool for evaluating RAG pipelines
- Reranking
- Cohere Rerank delivers best-in-class results for reordering retrieved chunks
- Model Serving
- Together AI: Supports most popular open models with good latency/performance
- Monitoring & Observability
- LangSmith: Powerful tool for LangChain-based pipelines (note: not open-source)
Context Quality is Everything
The effectiveness of RAG depends on what we put in context:
- Chunking: Controls what gets retrieved
- Metadata: Helps rank or filter retrieved chunks
- Retrieval Strategy: Directly impacts generation quality
Example: If chunks come from books, metadata could include the title or author to improve context relevance.
“As the retrieval goes, the generation goes.”
Final Tips
To improve RAG systems:
- Tune chunk size, embedding model, and ranking
- Leverage metadata to enhance relevance
- Optimize both retrieval and in-context input
This post is licensed under CC BY 4.0 by the author.